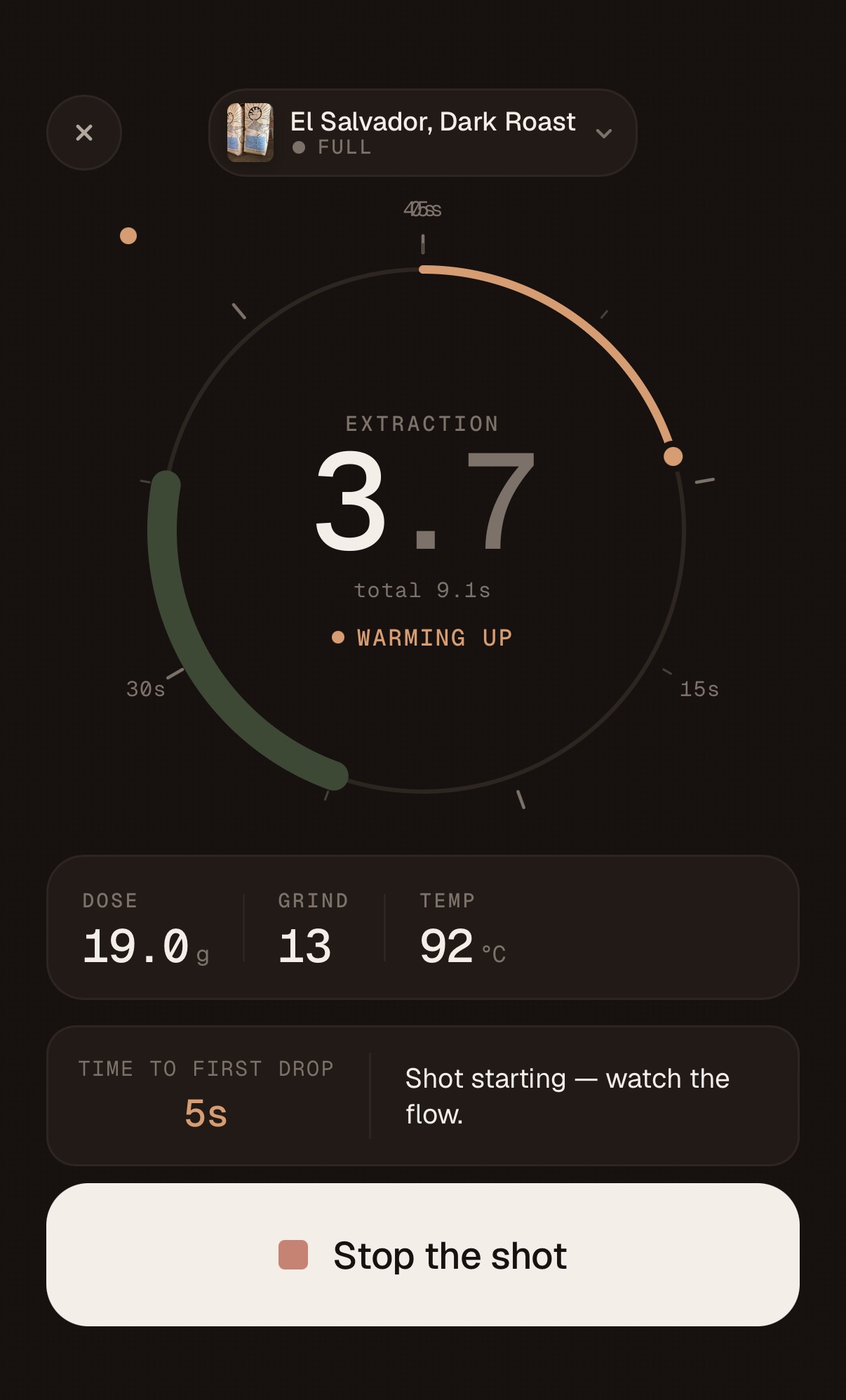
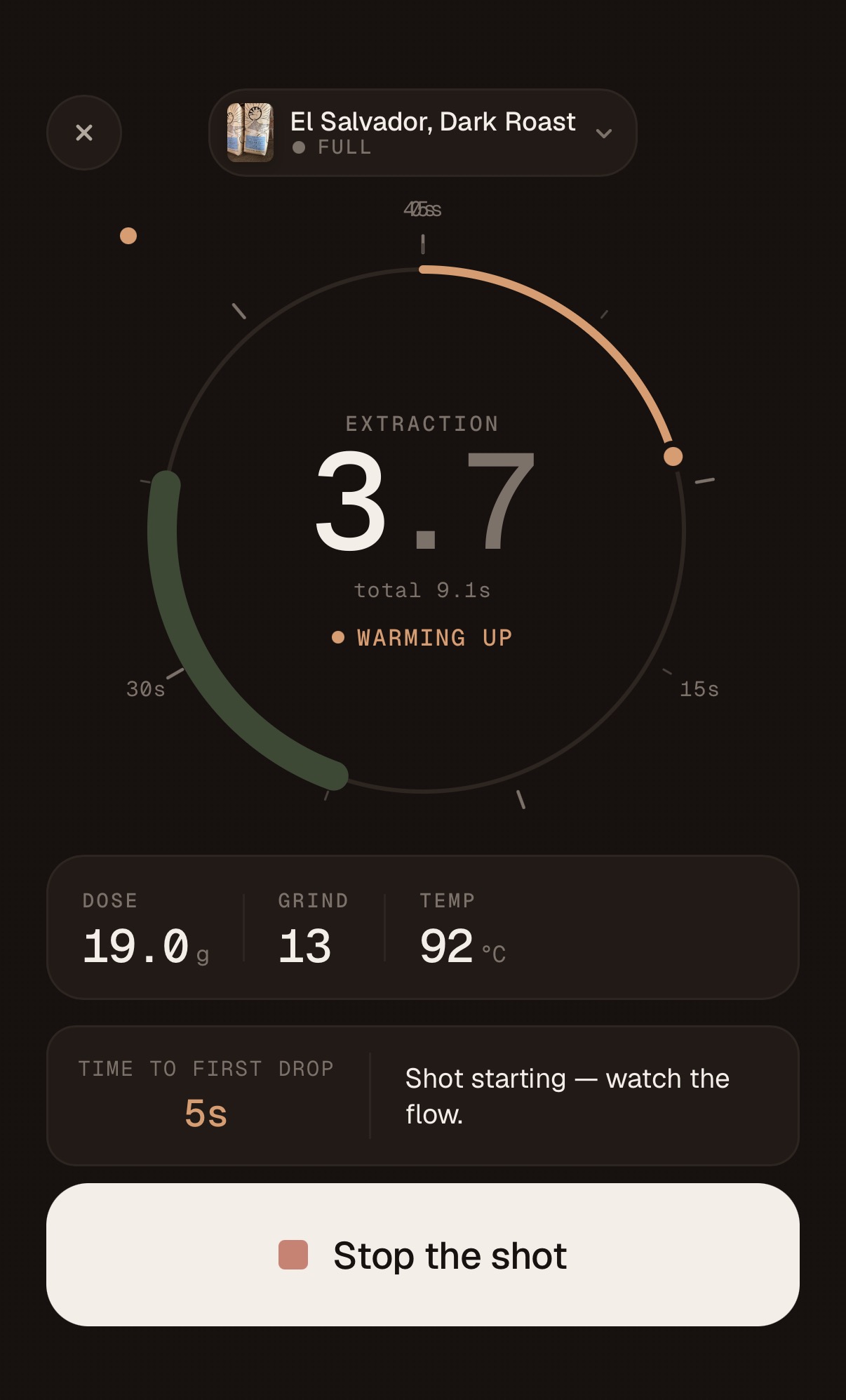
The next big feature is integrated the PullBook App with the Half Decent scale so I can completely automate the “pull a shot” workflow in the app but due to a shipping delay from Hong Kong all I have is a rough implementation and a simulator as shown below :
Status report – I gave the web site a bit of a makeover and improved the automation but nothing major. I also fixed a few minor bugs in the app and ended up in a bit of a merge hell. I have a branch open for the scales integration on one machine and working on bugs on another machine and at one point I just wanted the two Claudes to connect to each other and figure out how to move forward – relaying GitHub instructions through me was just slowing the whole process down and I don’t think I was adding much to the discussion. Anyway – everything got synched and committed and a new Apple TestFlight build is on its way.
I’m still manually onboarding beta participants – we’re talking small numbers so it’s entirely manageable but would love to automate this but away as well. My long term goal is to automate everything and reduce my role to design authority, product strategy, release planning / feature prioritization and any task that still needs a pair of hands to complete.
What this experiment has show me so far is :
I think my PM background and distance from the underlying tech is an advantage – there’s a strict division of labor between me (the what) and Claude (the how). I occasionally have to wade in with an opinion (usually in the form of a question) if I think the implementation may not be optimal. I’m equally open-minded and generally interested in Claude’s opinion of the what.
Everything is falling into place for self-improving / self-adapting software. Take the feedback, prioritize it, implement it, test it, ship it. Rinse and repeat. An external API changes or some other catastrophic bug – find it, fix it, ship the fix. All implemented with Claude in a local loop. There needs to be name for this.
At some point I need to invest a bit of time in automating the App store distribution – right now that’s very manual and requires XCode – my suspicion is that I will have to pay GitHub (for the OS/X images) or Apple – XCode Cloud and that would violate one of my requirements for this project that I don’t spend any money (beyond Anthropic tokens).
Reminder, if you are an Espresso aficionado, you might find the app very useful, more information here :
On these pages, I’m keeping notes of my experimentation with new AI based software development tools. My goal is to understand for myself whether tools like Claude and Codex are ready for developing commercial software. Low code and zero-code tools have been around for a decade or so – this is not the same. Vibe coding has been around for a few years as well – this isn’t the same.
This new approach has various names – agentic coding, spec driven development, personally I think “intent driven development” captures it best, though I’m confident that name won’t catch on. With intent driven development – I’m responsible for the what, the AI is responsible for the how.
As the cost and time to develop software shrinks, the focus will shift to other critical elements of the product lifecycle. I believe the next areas of differentiation for builder / product organizations will be:
Choosing hard problems to solve and solving them in ways that delight users. The easy problems can now be easily solved with a few well authored prompts and a vibe coding platform. Vibe Coding is incredible for solving small local problems – it’s the new Excel (and I mean that with a huge amount of respect)
Accelerating all the other toil related to building and product – pricing, training, marketing, enablement
Convincing enough people that your solution to the problem is the best. As time to market collapses, you have to assume competition and cheap imitation will be rife – how do you stand out ?
And so it is with my little pet project. I’ve invested 6.5 hours in the development of the application – included in that is some overhead in getting the development environment setup (GitHub automation, local Xcode), design, development and building regression test harnesses. For fun, I did a little costing analysis on the main code repo using scc – clearly COCOMO hasn’t really kept up with even pre-AI development tools but it’s a good way to reason about the magnitude in productivity – 8 months compressed to a week – even if the COCOMO estimate is out by a factor of 10 – the point still stands.
But that’s not really the point of this post. In my humble opinion, software development for low-stakes, greenfield problems are largely solved at this point and development time and cost is collapsing – it’s hard to debate this any longer and I personally don’t require any convincing. I don’t see an imminent plateau either – even if the models are throttled – agentic development can still scale in other ways. The way we develop software – heavily augmented with AI and human as the designer / orchestrator – that’s the way – there’s no going back.
So on to the next bottleneck – that’s pretty much everything upstream and downstream of software development. Software development is the tip of the spear in terms of agentic augmentation and performance improvement – everything else is next.
I spent a few frustrating hours this week downstream – fighting with the Apple TestFlight review process – clearly the user-centric design and detail to attention that Apple products are known for is pretty much absent from their developer tooling. I won’t belabor the point here but it’s classic “toil” – work that has to happen but brings you no joy at all. But it does highlight the point about the whole product lifecycle – everything has to get leaner and faster – it’s not going to be acceptable to wait three days for an App Store approval if the app only took a day or two to develop. You can’t spend a month on a marketing plan for a new release if the release will be out in two weeks. Everything has to speed up.
As part of the early access stage for my little test app – I needed an onboarding process. I could have used the Apple TestFlight defaults but want to own the onboarding and capture some user information in the process so I pretty much single-shotted a simple website (hosted on GitHub pages) and setup a Google form to capture registrations – not as automated as I’d hoped but mostly a one time cost.
Now I have the simple web presence – I have a home for the app’s change log so I got Claude to create an Action to create release notes every time I push a new release. The only twist here is that the Action calls out to Anthropic to turn PR text into human readable release notes – so far It seems to work well.
How we think about planning and project management will have to change. Even for a small one man project – normally there would be some planning involved but what I’ve learned this week is that if you have time to write a GitHub issue or a Jira ticket, then you probably have time to “do the thing” you were going to write the ticket about. What kind of planning is eve required in world of constant feature delivery – all you really need is direction / themes and prioritization.
The next thing I’m thinking about is how to take this experiment further – I have the first batch of beta users (you can sign up here if there are still slots available) and I expect to get some feedback – I’m hoping I can largely cut myself out of the loop. My goal is for Claude (or whatever) to present the work planned for the next release (new features, bug fixes, tech debt) based on customer feedback and product analytics – let me review it then just get on with the implementation, testing and delivery. Self improving software/ products / systems with human defined policy and guardrails – that’s where were heading. Sure someone still needs to inject strategy and innovation into the loop but product maintenance and improvement can be largely automated.
The next big feature is integrated the PullBook App with the Half Decent scale so I can completely automate the “pull a shot” workflow in the app but due to a shipping delay from Hong Kong all I have is a rough implementation and a simulator as shown below : Status report – I gave…
On these pages, I’m keeping notes of my experimentation with new AI based software development tools. My goal is to understand for myself whether tools like Claude and Codex are ready for developing commercial software. Low code and zero-code tools have been around for a decade or so – this is not the same. Vibe…
FWIW – my day job is running a largish (28 people) Product and Design team for Cellebrite. Cellebrite has nothing to do with Espresso – though some of the offices do have decent machines. I’ve been leading product teams for over 20 years and that background is driving how I develop software with Claude. For…
FWIW – my day job is running a largish (28 people) Product and Design team for Cellebrite. Cellebrite has nothing to do with Espresso – though some of the offices do have decent machines. I’ve been leading product teams for over 20 years and that background is driving how I develop software with Claude. For new feature releases I batch several related features (and bugs) and build them into a sprint – the sprint happens in a single branch. Sprints are 1-3 hours – usually on a Sunday when things are quiet. For major features I use plan mode judiciously – I rarely single-shot anything. While I have no desire to look at code (actually one of my goals) – I do want to understand how the design (technical and UX) is evolving and what the underlying data model is. I also have a medium term roadmap of sorts – and when I’m in plan mode with Claude – I’m constantly reviewing decisions related to the current work that may impact things I need to do in the future. This week’s Sunday sprint was a good example of that.
What I actually wanted was a more convenient way to sync data across devices (iPad, iPhone) – currently there’s a hack in place to back up and restore data to iCloud – it works but it’s a temporary hack. To access iCloud APIs – the app needs access to iOS native APIs so what I ended up doing was pulling ahead with the native wrapper work. I’ve been avoiding this because It adds a whole lot of Yak shaving – setting up an Apple Developer subscription, installing XCode, wrapping the react app with Capacitor, not to mention potentially breaking the app. In the pre-agentic world this would’ve been months of prep and work – now it’s the kind of thing you can pull off on a Sunday evening while half watching TV with wifey. The first step was planning – the work that needs to be done, the risk and mitigations – a few tweaks to the plan and go. The major worry was breaking the barcode reader – one of my favorites – the mitigation was pretty much a rewrite of that code. While Claude was coding – I set up XCode and signed up for an Apple Developer account.
After some jangling around in XCode trying to figure out how to get the app on my phone (without having to go via the App Store – something for another day) and backtracking to get the app icons in the right place. That small magical icon appeared on my screen. My first iOS app !
Click – nothing. Well not nothing, but the rendering was broken – somehow the screen dimensions were not taken into account so the app was visible just zoomed in to a region of the canvas with nothing on it – quickly fixed and redeployed. Straight to the home screen – loaded my current config and data and looked like everything was working – except dark mode – what happened to dark mode ? Another debug session and quickly fixed and redeployed. From visual inspection – everything looked to be working – probably 90 minutes to wrap a reactive app with Capacitor and change to native calls.
The thing I actually wanted was iCloud synching – so I started a smaller sprint to get that working. I thought it would be smaller – a fair amount of debugging was required here and I’m starting to think Claude really isn’t quite expert level (yet) – it has the breadth maybe, depth I’m less sure. It took some debugging and some design iteration but we got there eventually. I don’t think an expert would make the kind of mistakes I experienced during this sprint and it’s disconcerting when Claude admits – “oh yeh, I should have realized that function would fail if we hadn’t initialized the XYZ first”. Early days I guess. At some point – I may run the repo against another coding agent and get a second opinion on some of the design choices.
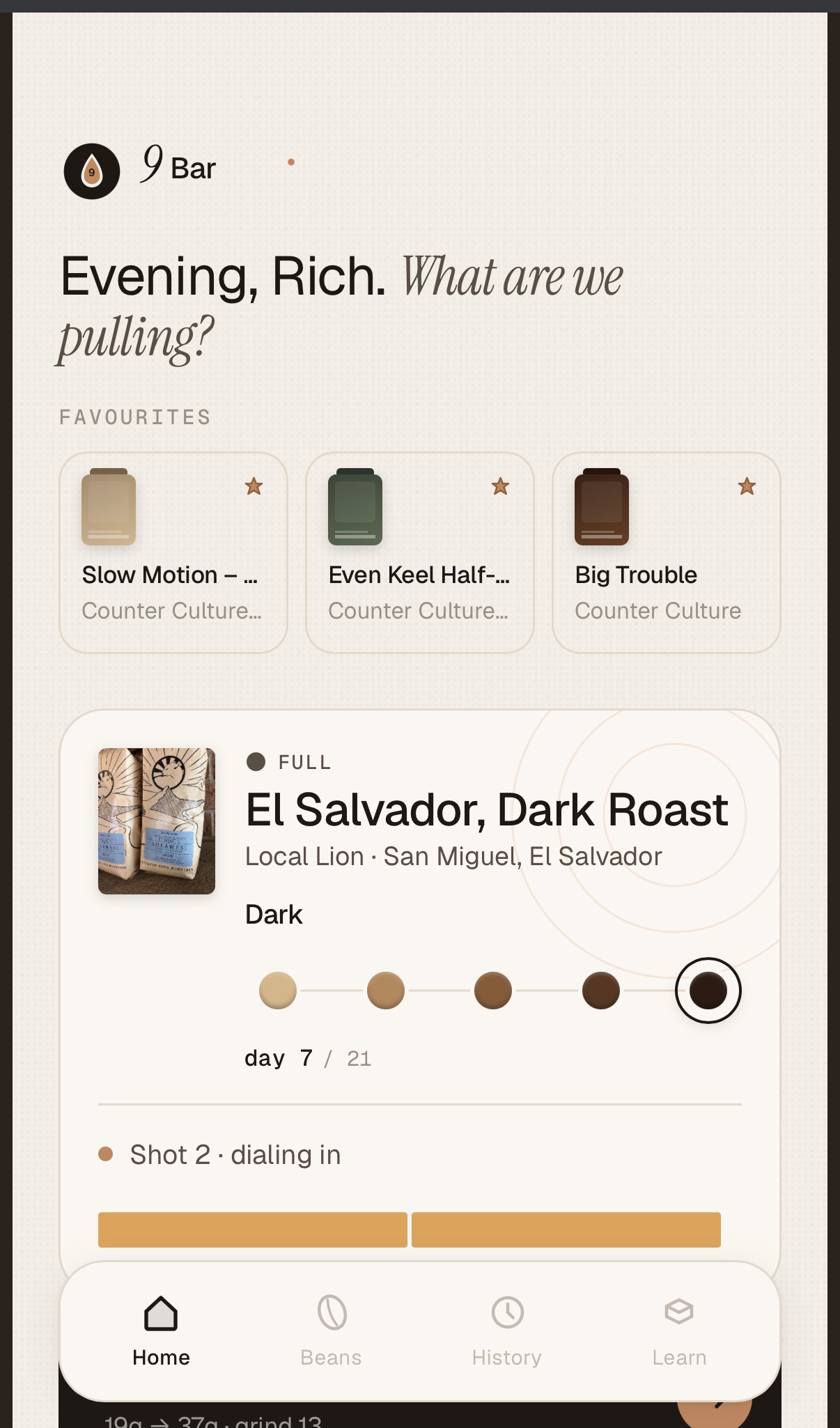
So I now have a fully functioning iOS native app running on iPad and iPhone with iCloud synching across devices. I’ve also published the app through TestFlight so if you are interesting in trying it you can sign up here. Part of the publishing flow discovered that the 9Bar name was already taken so had to rename the app – that was a lot of changes. Next time Claude suggests a name – I’ll ask it to verify domain names, app stores, USPTO, etc. Trust but verify !The next significant enhancement is integration with the Half Decent Scale – this will be a real test for Claude – this involves controlling a remote device over BLE.
At the start of the year I re-started my home espresso obsession having grown dissatisfied with the declining quality of Nespresso pods. This isn’t my first foray into home espresso and I’ve owned a range of machines over the years. I bought my self the entry level but pretty dependable Breville BES840XL and a one shot burr grinder – the Viesimple Gen 4.
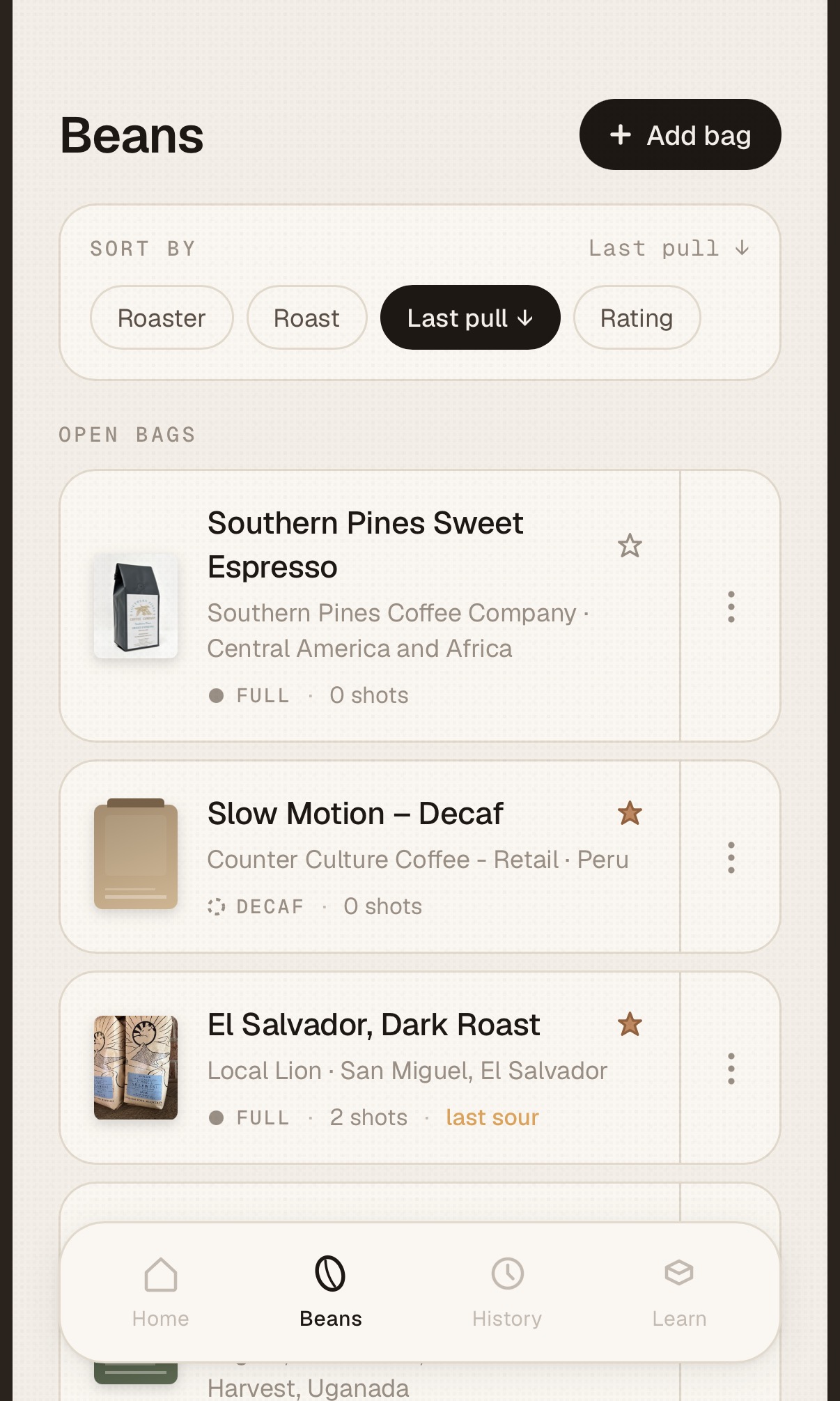
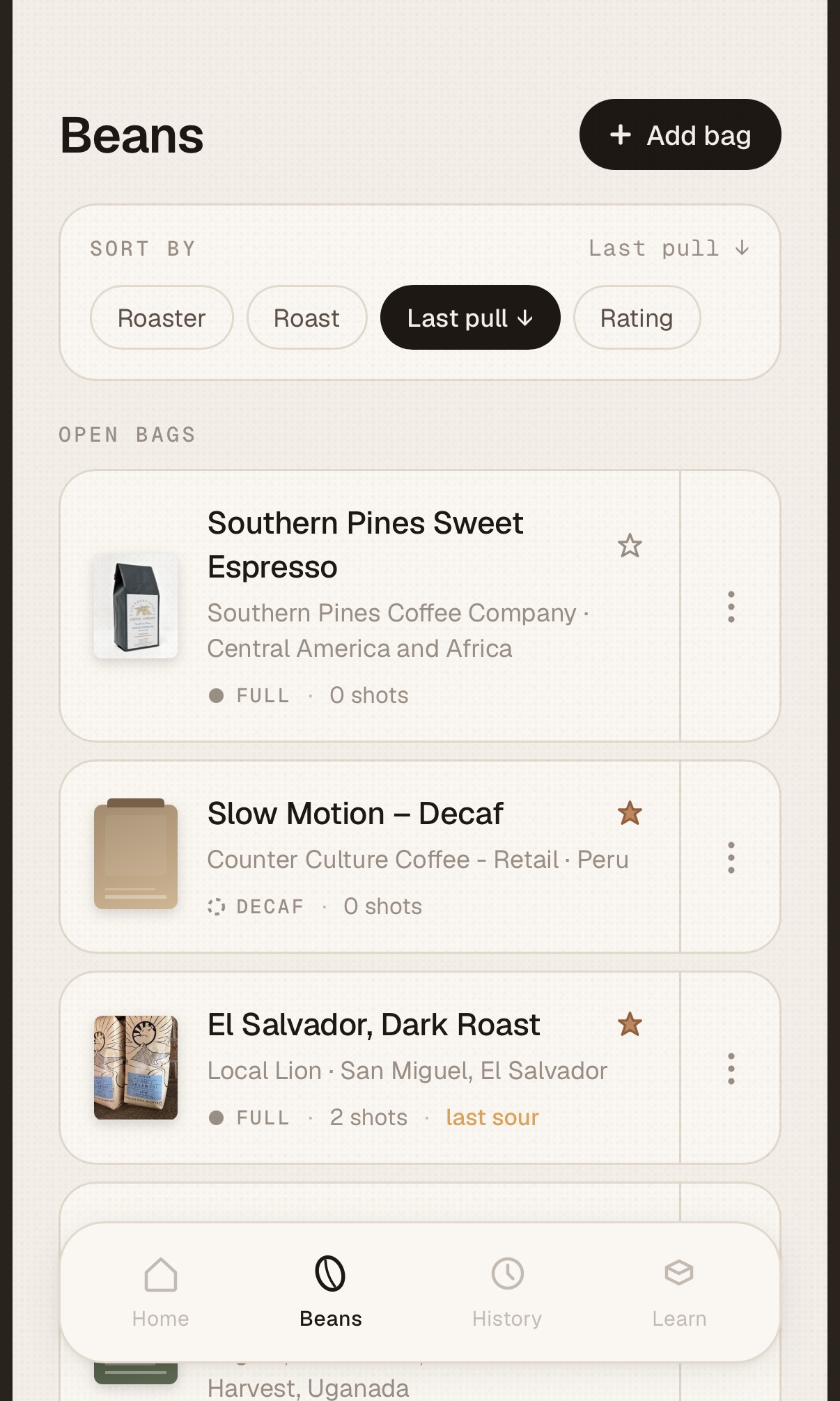
I have a couple of go-to beans from my local roaster (Counter Culture) but also like to try new roasts and usually pick up a bag or two when I travel. Every new bean takes a couple of shots to dial-in (grind, dose, pull duration, etc.) and I was keeping a log on Notes app, and scribbling the grind size on the label of the bean jar. A workable system but not ideal and not scalable.
About the same time, I was starting to play with LLM-based coding agents – Claude, GitHub Co-pilot, Codex, etc. and though it would be good to try a couple of real life software projects from ideation all the way through to delivery to get a sense of how the technology has evolved over the last couple of years. I learn best by doing.
So, over a rainy memorial day weekend I wrote a specification for a basic app to track my caffeine experimentation, used Claude Design to come up with mobile UX (iPhone and iPad) then brainstormed Claude Code on the best starter implementation and within a few hours and a few iterations – I had something working.
ScreenshotScreenshotScreenshot
After a few more weekend design and development sprints – I added a QR code scanner and URL scraper for adding new beans to my collection, created a flow for pulling shots and rating them and few other tweaks. Beta testing consists of pulling a morning shot using the app for a week then making changes the next weekend. I wish all beta testing tasted this good.
I’m now at the point where I think the app is actually useful and would like to share it with a few more people to get some feedback. If you are interested – leave a comment or drop me an email at sharps [AT] softwhere [DOT] org. It’s not a self contained iOS app (yet) and you need to be able to run the app on a desktop or laptop on your home network using npx (Node Package Execute) – if none of that means anything to you – you’ll need to wait a little longer for the native iOS app.
Some near term goals for the app :
Integrate it with the Half Descent Scale so the app can control the scale and also pull the timer and yield info straight into the app – I’m currently doing that manually
Re-order beans directly from the app.
Wrap or re-write the app so I can push it to the app store
Move the storage to the cloud so you can easily synch between devices
Why the cryptic name ? 9 bars of pressure is the gold standard for brewing authentic espresso.
OK a bit more agent wrangling on the two apps. over the weekend. Just a reminder : there’s a semi-serious app for producing 508 Compliance VPATs (A11yBot) and my lifestyle project 9Bar – which is basically an Espresso co-pilot / log book. For both projects I needed an easier way for people other than yours truly to access and run them without a build environment, so for now at least I went with npx – that means the any user can just :
npx @richsharples/a11ybot@beta
or
npx @richsharples/9bar@beta
For 9Bar – I plan to eventually convert it into a native wrapped iOS app and push it through the Apple AppStore with a hosted backend but for now a rea ct web app running on a machine on the local network works fine while I finesse the UX and the espresso pull logic / AI. For A11yBot – running locally with npx is probably good enough – people rightly have issues letting hosted scanners access their IP.
When I started on this journey I had a few of goals / principles in mind:
I’m not interested in looking at code, learning new frameworks, or remembering language syntax. When I was a full time developer many decades ago I took pride in knowing more then my peers and have always had a high tolerance for getting into the details. Not any more – I just don’t think that stuff matters any more.
While I’m a problem solver at heart – I don’t have a high tolerance for all of the accidental complexity and yak shaving that comes with modern software development – Git Syntax, GitHub actions, access tokens, npm publishing – it’s all incredibly awesome but like all good technology it just needs to fade into the background.
Have fun and learn something.
There is no doubt that Claude knows code, knows frameworks, can make good technology and architectural decisions and can work the local loop fine, but it is much less competent at understanding the more complex outer loop. I had to do a little research on the state of the art of publishing node packages from GitHub and provide a bit of direction. Not full on yak shaving but still a little frustrating and a lot of tokens burnt in vain. I do wish LLMs would occasionally pause and ask for help or guidance rather than just brute force ahead.
But let me put this in perspective – I spent a couple of hours on a Sunday afternoon, spent enough time on each project to implement a few more features – some trivial, some not so trivial, open sourced the A11yBot project under ASL 2.0, did a security and A11y review, wired up GitHub to build, scan and publish to npmjs.org when I cut a new release of either app. Without Claude – I probably would’ve got bored and given up at some stage – probably trying to fix some n00b syntax error. I certainly could not have achieved all of this within a few hours. This really is democratization of technology in action – right now, you still need to know a bit about the process of making software, but I’m sure all of this stuff will be significantly easier in the next 6 months.
Claude Opus 4.8 dropped on the Friday and I did switch over for a few sessions but whether it’s overloaded with users or has bigger issues I had to switch back to 4.7 for better stability. At one point Claude apologized that it had spent a lot of tokens on a design change that wasn’t needed and had to roll back the changes.
I’ve noticed I’m burning through tokens at an impressive rate – I’m not really tracking the costs it right now but suspect I’ll need to move to the Max 5x ($100 / month) plan and look at some of the tools for optimizing Claude code usage – I’m sure my current use of claude looks something like the picture above. But I’m having fun and that was one of my goals.
Although I haven’t been a full-time developer for well over 25 years, most of my career in product leadership has been in support of people building, deploying, and managing software systems, so I’ve always maintained a close interest in the art and science of software. With only a few exceptions—pretty much every year for the last 25 – I’ve managed to find a reason to actually write some code. I’m a big fan of learning by doing.
The early AI augmented co-pilots were very useful for someone who, like me, is not a regular coder and doesn’t have the time to learn the latest language, framework, or stack. The first vibe coding platforms were even more useful—producing running prototypes from simple prompts but the tools quickly became confused after a few iterations.
In the last 6 months, though—I feel like we’ve hit a significant step change in capability. On rainy Memorial weekend this year, I jumped into full AI development using Claude Design/Code, and I am pretty blown away with the speed and results.
Over the last 3 days, I developed two non-trivial apps—both of which would’ve taken me months to hand-code. Note in aggregate – I suspect I only spent about 5 or 6 hours actually developing software.
The work-related app
This first (A11yBot) is a web-based tool for completing Accessibility documentation (aka VPATs)—something most government customers require but part of the “whole product” that is usually de-prioritized. Yes, there are commercial apps, open-source apps and even commercial services for producing A11y report – but that’s not really the point – it’s a rich enough space to make a good target app.
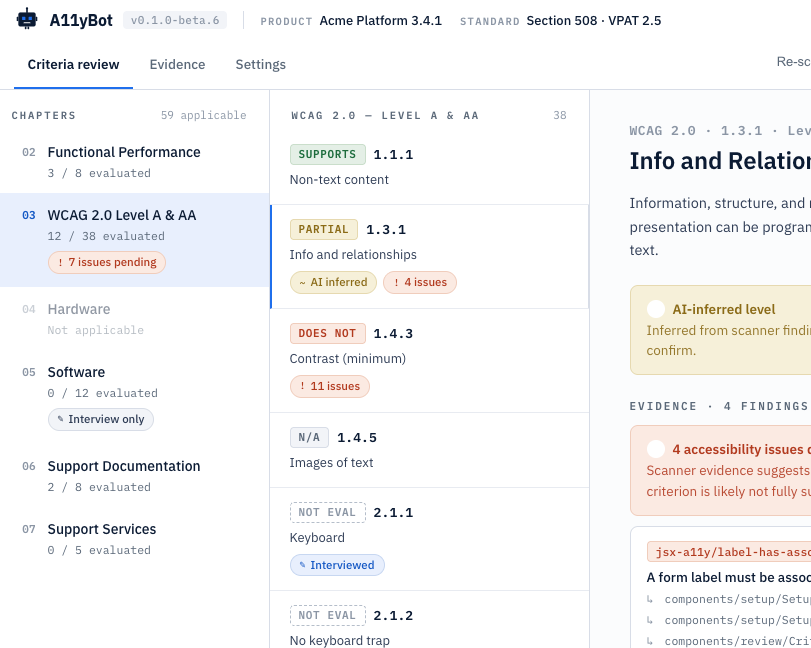
A11yBot Design
The A11yBot app runs locally, scans source code and a running web apps, and produces a VPAT report covering the standards you have selected. AI-generated responses synthesize the evidence from scans and completes the report. It supports the major Accessibility standards in the US and internationally. You can plug in an LLM for the AI response generation using OpenRouter or hook up to local models using Ollama APIs.
For this app – I started with a two-page-long specification outlining the MVP, goals (as automated as possible), and constraints (easy to run locally). From that, I asked Claude to produce a design – schema, workflow, and technology stack. Got the first working release in about 30 minutes and pushed it to GitHub as a baseline.
Running local models, scanners, test environment, and builds on a 24Gb M5 MacBook doesn’t work well, so I invested time in using the remote option in Claude Code so everything is running on a bigger Mac mini in my office. I have a suspicion that Claude leaks Chrome helpers as well – ended up with hundreds consuming about 70Mb each. Reboot time.
I also spent time trying different local models (via Ollama) for the report generation, then had Claude implement an OpenRouter API so I could use larger text models – huge improvement in speed and quality. Tldr – the big hosted models are a) much faster; b) produce much better outputs. You pay for what you get.
After several iterations – the app functioned well but looked like crap, so I opened Claude Design, asked it to do a design review (just needs access to code), and then to come up with a better design. Also added a dark mode switcher and took care of some outstanding A11y issues. It took about three more sprints (maybe 2 hours in total) to get all this work done, which required some restructuring and updates to the underlying data model, but this phase truly left me impressed. I realize Claude Design is still new, but it can already do some impressive work – I need to invest more time. Once Claude Design is fully integrated with Claude Code – it will be incredible – for now you just have to copy whole design briefs over and have Claude Code ingest them.
The A11yBot project is available on GitHub under – feel free to take it for a spin. If enough people are interested – I’ll invest more time in it and push it to npmjs to make it even simpler to run and probably license it under ASL2.0. Likewise – if anyone wants to improve on it – bring your robots !
The lifestyle app
The next app came off the long list of apps that I wish existed. I’m a bit of a home Espresso aficionado and go through a manual process of dialing new beans (dose, grind, extraction time, etc.) – the science/logic is well established, but I’ve never seen a decent application to make it easier.
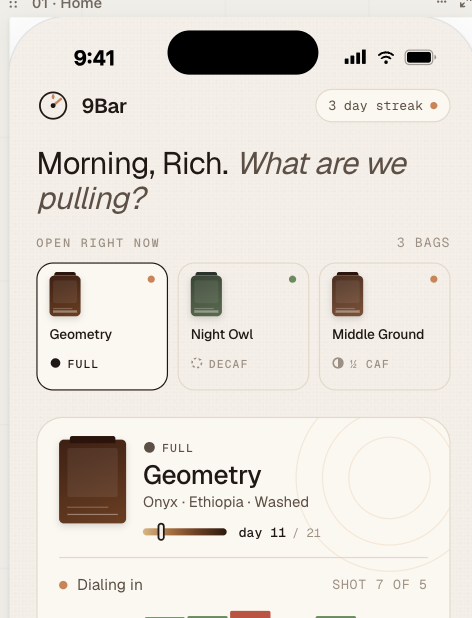
9Bar Design
Unlike the first app, I had a very good sense of how the app should behave, so I started in Claude Design (oops, ran out of credits) rather than diving straight into code gen. I started with a one-page specification describing the manual workflow and form factor – iPads, iPhone, and the areas I thought could be improved with an app.
MVP is:
loading a new bean – scans QR code and pulls details from the roasters’ website, or you can enter details manually.
Maintaining your Bean database (hopefully with the perfect extraction parameters).
Running an extraction, recording parameters like dose, grind, time, etc.
Taking user input on taste and giving advice on how to improve the next extraction.
I handed over the Design spec to Claude Code – asked it to come up with a schema and technical design and then let Claude go in full auto mode (oops, out of credits again).
I had to do a fair amount of debugging and research with this one (maybe 30 – 60 mins.) – especially the QR code reader. And I had to do two extra test shots to get the flow right – buzz!. I’m not making this repo public for now – need to iterate on it some more but may share it in the future. I also think this App will scale up well – the more people use it the more data on perfect extractions will be available without the need for experimentation.
Lessons Learned
A few things I’ve learned through this long weekend exercise:
For anything but minor fixes – do focused design / plan session – that gets you down to a very specific plan and goes much quicker
Maintain a regression suite. After major revisions, ask Claude to update regressions tests – I mostly do this for the data layer and APIs. Also, have some baseline reports to black box test end to end.
As long as I’m working on my own, I’m just working on the main branch though I’ve used feature branches for more speculative / risky stuff. Right now, I’m just letting Claude deal with GitHub.
Experiment in branches – code is now cheap – if the change doesn’t work, abandon the branch.
To do any kind of development, you need a $200 / month plan – I’m guessing full time devs are burning through $1000’s a month ??
Ask Claude to delegate visual testing back to you – watching Claude do testing via Chrome with screenshots is painful and very slow and no doubt burns tokens
Cost aside – code is cheap. I did start logging issues in GitHub for future work but quickly realized it takes only a little more (of my time) to ask Claude to code it.
If you have multiple machines – there are various ways you can leverage them – I’m using SSH to run stuff on my Mac mini while working on my laptop.
I find working in focussed sprints much quicker and less likely to exhaust / pollute the context window (mine and Claude’s!).
Batch up small fixes into a single prompt. This fits with how I work – I’ll run through the flow and make notes then ask Claude to fix them before the next iteration. Bigger stuff goes into a separate sprint.
Use /clear regularly – I use /clear as a matter of course when I’m starting a new “sprint”
The collapsed feedback loop is a true game changer – you can sit down with a user (myself included, in this case) and iterate in real time.
I’ve become acutely aware of token costs and have already started reading tips on token frugality.
Note – I’ve used the word sprint here – to me that’s a focussed batch of work with some outcome but instead of taking 2-3 weeks – it takes between 5 and 15 minutes with Claude.
In a previous life, I was a developer for about a decade – Assembly, C / C++, Fortran, Smalltalk, Java, I used to love developing software – you get a real sense of accomplishment but I never had the patience for the yak-shaving, obscure language syntax or arcane behaviors of someone else’s framework. Removing coding tasks from software development has been a dream for decades but we’re getting dangerously close to finally achieving it IMO.
After very convenient coffee and breakfast across the road from our hotel, we packed up our wet gear, loaded up on snacks and water and loaded up the minivan of the hotel manager who offered to ferry us back to the C&O to avoid the sktchy road detour. FWIW – you can get six people + gear and five bikes in / on a minivan with a 3 bike rack. Not pretty, probably not safe, but doable.
The last leg was less than 70 miles but we were all feeling pretty knackered after four days of riding. We stopped at White’s Ferry for sandwiches about half way then cruised into the suburbs of DC. The highlight was Great Falls so we stopped a few times for some sight-seeing.
Finding mile 0 of the C&O in Georgetown was a little challenging – unless you know where to look it would be difficult to find. It’s tucked away on the river bank behind the Georgetown University Boathouse.
After a few photos and celebratory fist-bumps, we then had to ride another 5 miles or so to pick up the truck and our gear we’d stashed at a friend’s house in the DC suburbs. We had a quick beer in the sun while I checked into my flight to London that same night. The other four guys we’re staying overnight so I borrowed a hotel room for a quick shower and a change of clothing. We went out for a well deserved celebratory curry and then I went straight to Dulles for my red-eye to London.
We were very lucky with the weather, had no injuries and the only mechanical issue was a blow out which sealed itself after spraying a few of use drafters with tire sealant.
Huge thanks to the gang – David, Iain and Sean and especially Bryan and ChatGPT 🙂 for managing the logistics and to Tim for letting use his house as a staging post. I’d definitely recommend the GAP C&O – it’s not just a trip through some amazing scenery but also a trip through time – from Civil War battlefields to America’s industrial revolution – there are few places in the US so steeped in it’s history.
We ate left-over pizza for breakfast as nothing else was open. Stopped in Williamsport to find a bike shop, coffee and food. Bike shop was closed but we found a decent little cafe and loaded up on carbs and caffeine.
The weather forecast wasn’t looking good and we wanted to get to Harper’s Ferry before the rain caught us so we hammered through the morning with just a few short stops. Passed pretty close to my namesake – Sharpsburg – famed for being the site of the Battle of Antietam, the bloodiest single day of American Civil War. By lunchtime the rain had caught us so we pulled off the C&O to eat a decent lunch in the little college town of Sheppardstown. For the first time – pulled on my rain jacket and we spent the next few hours getting pretty soaked. When we reached Harpers Ferry we had to do a pretty hilly and very sketchy detour in busy traffic as the bridge over the Potomac was closed for repairs.
Arrived at our funky little hotel pretty soaked and tried to get everything hung up to dry before venturing out for dinner and re-hydration. The detour added a few extra hilly miles – topping out the day at 74.2 miles.
Did a quick recce into town to find some decent coffee (Clatter Cafe) and warm up the aching legs – it seems that every road in Frostburg us uphill in both directions. A hearty breakfast and a chat with the owner of the Allegheny Trail House about the trail ahead of us. Then re-packing, a bit of bike maintenance and we were off – at 77.3 miles – this was our longest distance but having crossed the continental divide we were mostly heading downhill or flat.
It was a pretty damp start but we managed to dodge the rain. First stop was Cumberland where the GAP and the C&O connect and there’s a well stocked bike shop right on the trail. Cumberland is a good place to stock up on snacks as there aren’t too many food options for the next 50 miles or so.
Our lunch stop was the School House Kitchen in Oldtown – very basic food but it did the job. I suspect this place only stays open due to it’s proximity to the C&O trail – like a lot of the towns you pass through on the GAP and C&O the collapse of the mining, steel, and coke industry is a big economic gap to fill. Reminds me of areas in the North of England – similar landscape, remnants of the industrial past and signs of economic distress.
The big event of the day was the Paw-paw tunnel (3,118-foot-long canal tunnel and significant feat of engineering). To ride this without lights would be very difficult – the surface is rutted and washed away in places. Stopped for coffee / break at Bills Place in Little Orleans only to find out it’s been closed for about 5 years. Hammered through to Hancock and our AirBnB for the night.
Hancock a decent sized town but it was mostly closed down (I guess it’s a seasonal town) so it was Pizza Delivery, beers from the gas station and a night of laundry and yup – you guessed it – Five Crowns.
Despite drawing the short straw and sleeping on the couch, I had a pretty decent night’s sleep. Note – trying to find AirBnBs for 5 people is more challenging that you’d think. After coffee at the eclectic Crawford Coffee followed by a decent breakfast in the Valley Dairy we packed up and got back on the trail – rode the first few miles with a couple of riders from Texas and Canada. Today was going to be our 2nd longest day in the saddle (76.8 miles) and slightly uphill to the highest point of the ride at the eastern continental divide.
On the way we stopped for views of the river from the many steel bridges and stopped for a coffee break in Ohiopile then onto the Eastern Continental Divide (water at this point flows into the Gulf of Mexico on one side and the Atlantic on the other). Through the big savage tunnel (one of three long tunnels – you’ll be glad you bought lights!) then some history / culture as you cross the Mason-Dixon line. A punchy set of climbs off the GAP Trail got us to our rest stop for the night in Frostville – the very funky Allegheny Trail House. We were all pretty starving after a long day in the saddle – so a quick shower, hosed the bikes down and headed for dinner at the local Mex followed by the usual end of day entertainment – 5 Crowns !